Server-Side Tag Management: Six Myths Debunked
Server-Side Tag Management: : Server-based data collection in digital marketing is not new. But when browser limitations are multiplying and personal information requires more security, it offers many advantages. However, this approach also raises some concerns and misunderstandings. The following six misperceptions in terms of server-side tag management keep popping up:
Table of Contents
1. The End Of Tag Management
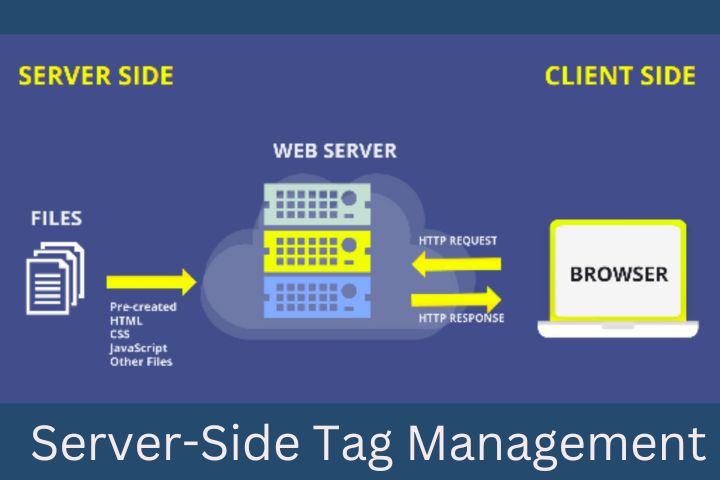
There are two web data collection approaches: client-side and server-side. In the first approach, the operations take place on the client side of an end device – usually within a browser. When a browser loads a page, tags are fired, and scripts are served by a tag management system (TMS) and executed in the browser. So the browser does most of the work. It collects the data, processes it, and “talks” directly to the service providers that correspond to the tags. If 40 tags are embedded in a page, the browser sends data to the 40 designated services.
In “server-side” mode, as the name suggests, everything happens on the server side. Instead of 40 data transmissions (assuming all tags are processed on the server side), the browser sends only a single request to the relevant service – and that’s it! The TMS does not return scripts for execution. All processing takes place on the server side: the preparation of the data and its distribution to the various partners.
When browsers are becoming more strict about cookies, the server-side philosophy offers significant technological advantages.
The server-side solution is also often referred to as the “tagless” approach. This implies that tags will disappear as server-side tag management takes hold. However, in the current state of the digital landscape, the coexistence of the two approaches remains critical. Because while server-side tag management is already used in social media, affiliate marketing, web analytics, or consent transmission, implementation with ad servers or personalization solutions is more complex. The transition takes time. So the tags don’t disappear that quickly.
2. For IT Teams Only
With the advent of server-side solutions, the perception is that tracking is moving from the marketing to the technical teams.
However, this is a significantly shortened perception. Yes, server-side tag management relies on API logic. This could give the impression that this topic is more suitable for code-savvy colleagues. If you look beyond the technical aspects of a server-side solution, the question arises, what is it actually about? Simply, to sustain digital activities by understanding customer behavior, improving the customer experience, and optimizing marketing campaigns. This task is more important than ever and is part of the digital team’s work. And even if the implementation of this “tagless” approach has changed working habits and created new technical terms, the essential requirement ultimately remains the same:
3. Server-Side Technologies Offer Less Control
An understandable feeling. It stems from the first touch points between each team and this technology. Employees’ habits with browser-side tags provide a sense of familiarity and control.
With server-side managed technology, this overview seems to be a thing of the past. But only apparently. In practice, the new server-side marketing platforms improve essential aspects such as data governance, quality control, and data enrichment.
The goal is to streamline the legacy way of working to accommodate the growing maturity of digital teams. The tag management platform is still the “hub” where the data is collected, processed, and transmitted to partners. Instead of managing tags, however, a “tagless” solution drives server-to-server integrations without sacrificing readability and control.
4. Server-Side Solutions Mean The End Of Consent Management
Server-side tag management is a technical process for collecting and processing data. It does not change the precautions that need to be taken to comply with the General Data Protection Regulation (GDPR) and the guidelines of national data protection authorities for obtaining consent. Regardless of whether a browser or a server transmits the data, the user must give their support.
If the consent requirements remain on the server side, things are different with ad blockers. As a reminder, these plug-ins use blocklists that block certain services from being accessed via the browser. Since the calls are made from the server on the server side, they do not fall within the scope of ad blockers. Since the service called on the server side can be hosted on a website subdomain (not on a third-party domain), mechanisms such as ad blockers do not intercept it either. The concept also avoids other disruptive technologies, such as ITP (Intelligence Tracking Prevention), as most work happens on the server without needing third-party cookies.
5. Working On The Code On The Server Side Is Even More Delicate Than On The Client Side
Changing tags, especially during peak periods (for example, Christmas shopping), has been risky. Some did not hesitate to do a code freeze so that the code would not allow updates in data collection and processing.
Server-side tag management offers a healthier architecture: client-side the bare minimum (measuring with a single tag) and server-side most of the processing.
Before the data is sent to an external party, it can be modified (IP addresses can be anonymized or removed entirely) or enriched with relevant information, such as segmentation, payment, or subscription values. Article numbers or product data can also be added to the data record before it is forwarded. A division of labor is often summarized as device-based measurement and cloud-based processing. In concrete terms, teams can make server-side changes even at sensitive times without touching the client-side code.
6. The Confidentiality Of The Data Is Tightened On The Server Side
When it comes to security, nothing can be taken for granted. Just because interactions are managed server-to-server doesn’t mean they’re inherently more secure. This is when the infrastructures are checked and secured according to best practices, and the data traffic between the servers has a proper encryption mechanism.
Depending on the technical precautions taken, it should be borne in mind that a data layer can remain in the browser and thus disclose data.
When it comes to sensitive information, the server-side model can help keep that data outside the client: it is loaded onto the server via an API or CSV import in addition to the client-side data, eliminating interaction with the client. Data security is, therefore, significantly enhanced.